
JSON 파일로 변환하는 것까지 해결했다. 속도도 괜찮은 수준으로 만들었다.
16초.. 그리고 주소가 키 값으로 한 딕셔너리를 만들었다.
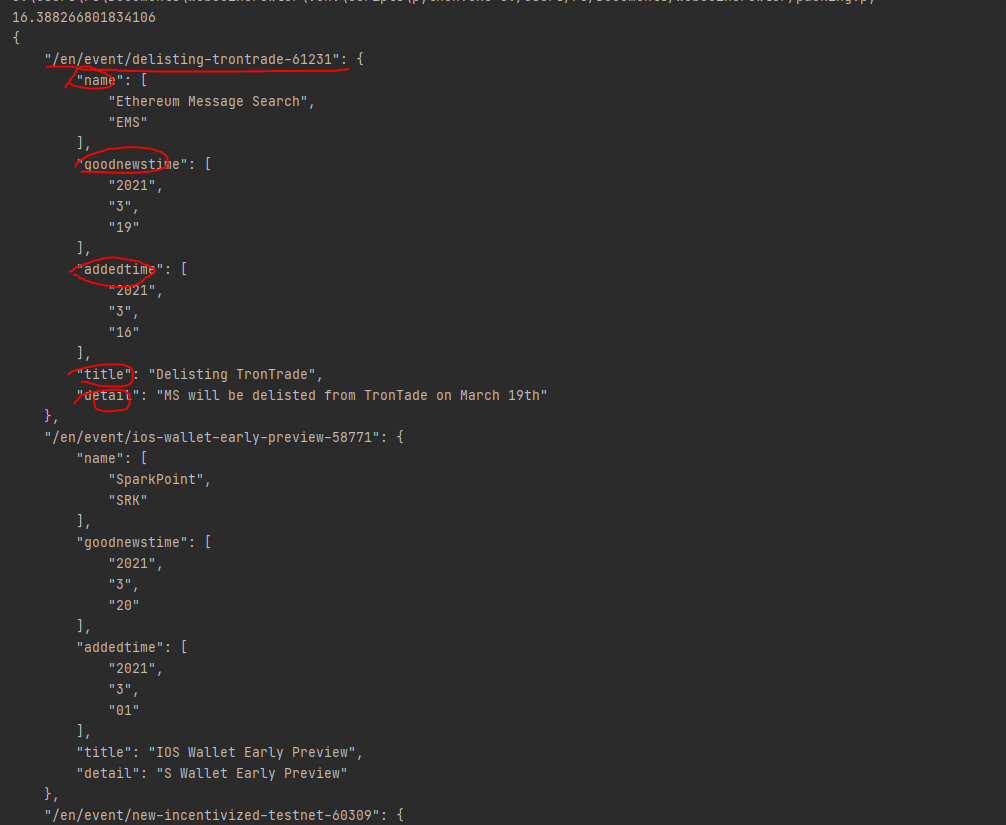
해결 한 문제
JSON 파일로 변환하기 위해서 데이터를 딕셔너리 형태로 바꾸어주어야 했다. 리스트도 할 수 있다고 쓰여져 있긴 했는데 구글링 해보니깐 거의 딕셔너리로 만들었길래 딕셔너리 변환을 해주었다. 데이터 1개를 포장해야할 키 값으로 url을 사용했는데, url값은 그 정보의 전체 데이터를 나타내고 고유한 값이기에 key로 사용하면 적합하다고 생각했고, 이 또한 크롤링 후 전처리를 통해서 str형태로 바꾸어 주었다.
마주친 문제
find함수 쓸 때 주의 사항
"ATBT"
find('T', 2)하면 인덱스 3을 출력한다. 2라는 인자가 2번째 T를 찾아주는 줄 알았다. 하지만 2라는 인자는 인덱스 2번 부터 탐색을 시작한다는 뜻이었다. 결국 두번째 T를 찾으려면 다른 방법을 찾아야 했다. 왜냐면 첫번째 T가 어디인지 찾아서 그 인덱스 부터 탐색을 시작하도록 한다면 복잡해질 것이다. 찾다보니 문자열을 탐색할 수 있다는 것을 알았고, find("str")이렇게 그냥 사용하면 된다.
깃허브 초대 받을시 레퍼지토리 생성 안됨
조금 헤맸는데 결론은 fork를 쓰는 거였다.
구글에 검색하면 바로 나온다.
우측 상단에 fork를 누르면 내 저장소에 생기게 된다.
전체 코드
import json
import os
import sys
from urllib.request import urlopen
from bs4 import BeautifulSoup
import multiprocessing
import time
import re
month = {'Jan': 1, 'Feb': 2, 'Mar': 3, 'Apr': 4, 'May': 5, 'Jun': 6, 'Jul': 7, 'Aug': 8, 'Sep': 9, 'Oct': 10, 'Nov': 11,
'Dec': 12}
def getPageNumberFromcoinmarketcal():
html = urlopen("https://coinmarketcal.com/en/")
soup = BeautifulSoup(html, "html.parser")
coin_maxpage_data = soup.select("a[class='page-link rounded']").pop()
coin_maxpage = re.findall("\d+", str(coin_maxpage_data))
return int(coin_maxpage.pop())
def packingDataFromcoinmarketcal(page_number, result):
proc = os.getpid()
url = "https://coinmarketcal.com/en/" + "?page=" + str(page_number)
html = urlopen(url)
# # 사이트에 문제가 있으면 함수 종료
# if html.status != 200:
# return
soup = BeautifulSoup(html, "html.parser")
# 정보 -> 이름, 호재 시간, 추가된 시간, 제목, 상세내용
coin_key_data = soup.select("article.col-xl-3.col-lg-4.col-md-6.py-3 > div.card.text-center > div.card__body > a.link-detail")
coin_name_data = soup.select("article.col-xl-3.col-lg-4.col-md-6.py-3 > div.card.text-center > div.card__body > h5.card__coins > a.link-detail")
coin_goodnewstime_data = soup.select("h5[class = 'card__date mt-0']")
coin_addedtime_data = soup.select("p[class = 'added-date']")
coin_title_data = soup.select("article.col-xl-3.col-lg-4.col-md-6.py-3 > div.card.text-center > div.card__body > a.link-detail > h5.card__title.mb-0.ellipsis")
coin_detail_data = soup.select("p[class = 'card__description']")
min_len = min(len(coin_name_data), len(coin_goodnewstime_data), len(coin_addedtime_data), len(coin_title_data),
len(coin_detail_data))
# 전처리 이름[이름, 태그], 호재 시간[년, 월, 일], 추가된 시간[년, 월, 일], 제목[문자열], 상세내용[문자열]
# 전처리 후 패킹
for i in range(0, min_len):
#딕셔너리 키 값
coin_key = str(coin_key_data[i])
coin_key = coin_key[coin_key.find('href="') + 6 : coin_key.find('" title')]
# 이름 전처리
coin_name = ' '.join(coin_name_data[i].string.split())
coin_name = [coin_name[0: coin_name.find('(') - 1], coin_name[coin_name.find('(') + 1: coin_name.find(')')]]
# 호재 시간
coin_goodnewstime = coin_goodnewstime_data[i].string.split()
coin_goodnewstime = coin_goodnewstime[:3]
coin_goodnewstime[1] = str(month[coin_goodnewstime[1]])
coin_goodnewstime.reverse()
# 추가된 시간
coin_addedtime = coin_addedtime_data[i].string.split()
coin_addedtime = coin_addedtime[1:]
coin_addedtime[1] = str(month[coin_addedtime[1]])
coin_addedtime.reverse()
# 제목
coin_title = str(coin_title_data[i].string)
# 상세내용
coin_detail = ' '.join(coin_detail_data[i].string.split())
coin_detail = coin_detail[2 : len(coin_detail) - 1]
# 패킹
item_coin = {
'name': coin_name,
'goodnewstime': coin_goodnewstime,
'addedtime': coin_addedtime,
'title': coin_title,
'detail': coin_detail
}
result[coin_key] = item_coin
if __name__ == '__main__':
start_time = time.time()
manager = multiprocessing.Manager()
result = manager.dict()
indxs = [i for i in range(1, getPageNumberFromcoinmarketcal() + 1)]
procs = []
for i, v in enumerate(indxs):
proc = multiprocessing.Process(target=packingDataFromcoinmarketcal, args=(v, result))
procs.append(proc)
proc.start()
for proc in procs:
proc.join()
print(time.time() - start_time)
print(json.dumps(result.copy(), indent="\t"))
해결해야 할 문제
원래는 여기 정도까지가 나의 목표였다. 하지만, 장고에 데이터를 저장하는 것까지 하기로 했다.
하지만 장고를 모른다.
장고를 공부하기로 했다..!
'프로젝트 > COHO - 코인 호재 캘린더' 카테고리의 다른 글
| [Django] 코호 - 실시간 코인 호재 모음 PROC 7 (0) | 2021.03.19 |
|---|---|
| [Django] 코호 - 실시간 코인 호재 모음 PROC 6 (0) | 2021.03.19 |
| [Django] 코호 - 실시간 코인 호재 모음 PROC 4 (0) | 2021.03.17 |
| [Django] 코호 - 실시간 코인 호재 모음 PROC 3 (0) | 2021.03.17 |
| [Django] 코호 - 실시간 코인 호재 모음 PROC 2 (0) | 2021.03.17 |